Introduction
1. Introduction
L’objectif de cette partie est de vous familiariser avec les différents microservices de l’application Crazy Train. Vous allez modifier le code de plusieurs projets Quarkus, Python et Nodejs, comprendre comment ils interagissent et tester l’application dans son ensemble.
L’image ci-dessous décrit le fonctionnement global
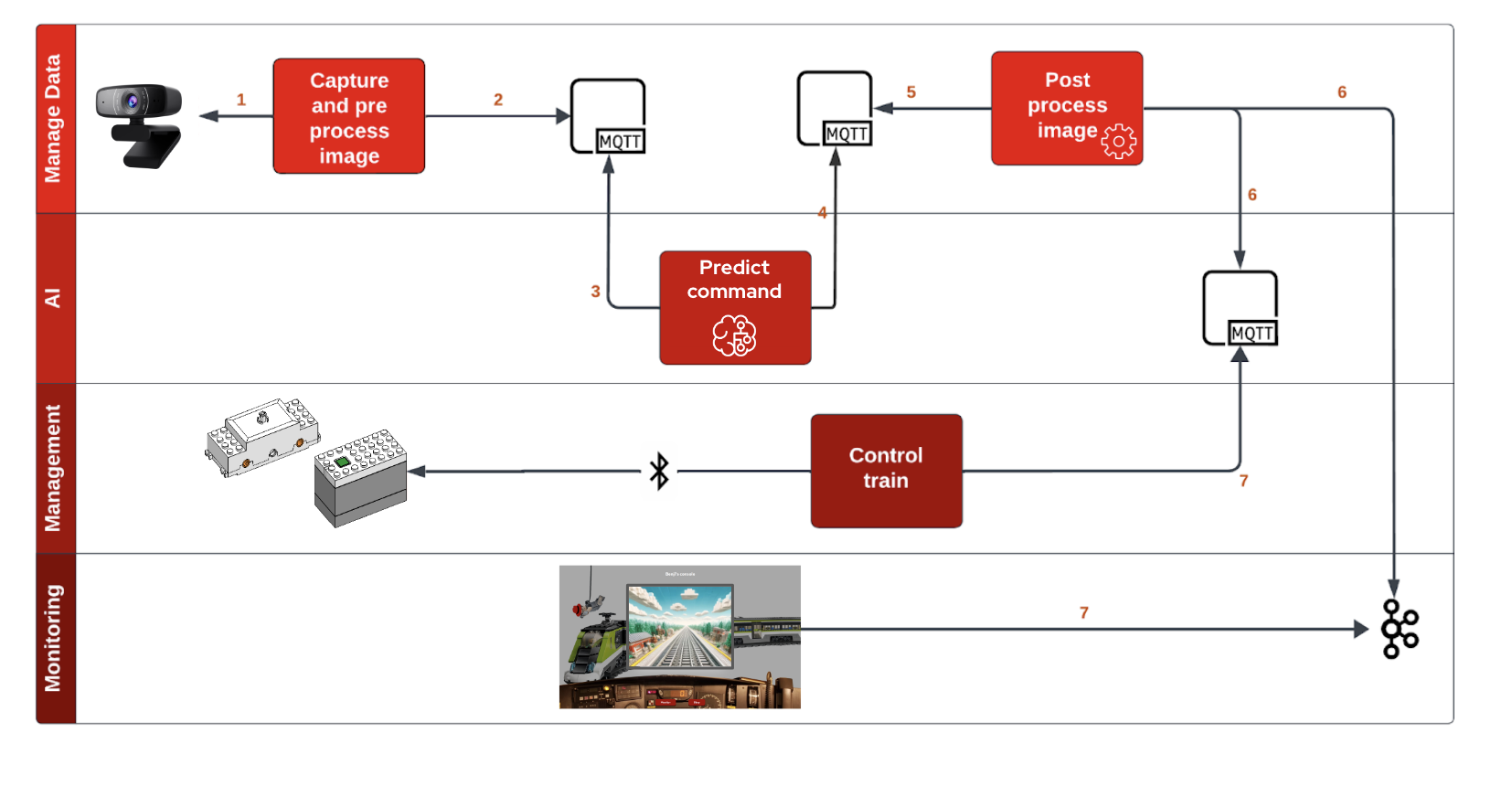
Voici une description de chaque service :
Capture and process image (projet capture-app): Il s’agit d’un service Quarkus qui permet de démarrer, de tester et d’arrêter la capture vidéo. Il expose des points d’extrémité RESTful qui peuvent être appelés par d’autres services ou clients pour contrôler la capture vidéo.
Predict command (projet intelligent-train): Ce service est chargé d’analyser les données de la vidéo capturée. Il utilise des techniques d’apprentissage automatique pour interpréter les données vidéo et fournir des informations basées sur cette analyse.
Post process image (projet train-ceq-app): il s’agit d’un service de gestion des événements qui reçoit des informations du train intelligent et d’autres services, et qui déclenche les actions appropriées. Par exemple, si le train intelligent détecte un obstacle sur la voie, le service déclenche un événement pour arrêter le train.
Control Train (projet train-controler): Comme son nom l’indique, ce service est responsable du contrôle du train lui-même. Il reçoit des commandes de services tels que train-ceq et effectue des actions sur le train, telles que le démarrage, l’arrêt, la modification de la vitesse, etc.
Monitoring (projet monitoring-app): Ce service est responsable de la surveillance de l’ensemble du système. Il recueille les données de tous les autres services, telles que les événements déclenchés, les actions effectuées, l’état du train, etc. et fournit une vue d’ensemble de l’état du système. Il pourrait également fournir des alertes ou des notifications en cas de détection de problèmes.
Chaque service est indépendant et communique avec les autres de manière asynchrone (MQTT/Kafka). Cela permet une grande flexibilité et une grande évolutivité, car chaque service peut être développé, déployé et mis à l’échelle indépendamment des autres.
2. Votre environnement de laboratoire
Vous allez utiliser OpenShift Dev Spaces. OpenShift Dev Spaces utilise Kubernetes et les conteneurs pour fournir un environnement de développement cohérent, sécurisé et sans configuration, accessible depuis une fenêtre de navigateur.
Utilisez le lien suivant pour générer votre environnement OpenShift Dev Spaces :

Connectez-vous avec vos identifiants OpenShift (userX/mot-de-passe). Si c’est la première fois que vous accédez à Dev Spaces, vous devez autoriser Dev Spaces à accéder à votre compte. Dans la fenêtre Autoriser l’accès, cliquez sur Autoriser les permissions sélectionnées.
Cela ouvre l’espace de travail, qui vous semblera assez familier si vous avez l’habitude de travailler avec VS Code. Avant d’ouvrir l’espace de travail, une fenêtre contextuelle peut apparaître pour vous demander si vous avez confiance dans le contenu de l’espace de travail. Cliquez sur Oui, je fais confiance aux auteurs pour continuer.

Attendez que l’espace de travail soit disponible, ce qui prend quelques minutes pour mettre en place un environnement de développement complexe avec plusieurs services (Kafka, Zookeeper, Mosquitto), les outils (OpenShift CLI, Maven, Python, Node.js), et s’assurer que toutes les dépendances nécessaires sont installées (comme OpenCV).
Dans l’explorateur de projets situé à gauche de l’espace de travail, naviguez jusqu’au dossier opentour2024-app et regardez les différents projets.
